Table of Contents
1 | Introduction to Design Tokens
2 | Managing and Exporting Design Tokens With Style Dictionary
3 | Exporting Design Tokens From Figma With Style Dictionary
4 | Consuming Design Tokens From Style Dictionary Across Platform-Specific Applications
5 | Generating Design Token Theme Shades With Style Dictionary
6 | Documenting Design Tokens With Docusaurus
7 | Integrating Design Tokens With Tailwind
8 | Transferring High Fidelity From a Design File to Style Dictionary
9 | Scoring Design Tokens Adoption With OCLIF and PostCSS
10 | Bootstrap UI Components With Design Tokens And Headless UI
11 | Linting Design Tokens With Stylelint
12 | Stitching Styles to a Headless UI Using Design Tokens and Twind
What You’re Getting Into
Alright, so far I’ve written a lot about the process of creating an automated design tokens pipeline across the range of applications within a company.
That’s all cool stuff.
The idea of creating design tokens that can be exported as platform deliverables across different platforms and technologies is neat. It will likely shape the future of app development, leading to increased productivity and communication between designers and developers.
But, it’s time for some real talk.
Creating an automated design tokens pipeline does not ensure that a design system has been adopted.
How can you ensure that a design system has been properly adopted?
Whichever way you slice it, it comes down to manual testing. Regardless of whether that is done by a QA team, the design system team, or the developers of a team, it comes down to manual testing.
We can categorize the manual testing into acute and chronic testing (I just went to the dentist and medical terms are on my mind apparently).
Acute, or short-term, testing will likely occur when there is an initiative to adopt a design system led by the design system team.
Let’s give an example.
You are working for a company called “ZapShoes,” the world’s fastest way to have shoes delivered to your home. Specifically, you are working on the design system team and are tasked with overseeing an initiative to have all applications within your company adopt a new design system.
Imagine you’ve even been able to successfully build out an automated pipeline to deliver design tokens to consuming applications.
Each stakeholder representing a consuming application is notified that they have 1 month to adopt the new design tokens, meaning 1 month to make the application match the design system.
After this project ends, there will be a sudden, short-term period of testing, scoring how well each consuming application has adopted the new design tokens.
This may look similar to a UX scorecard.
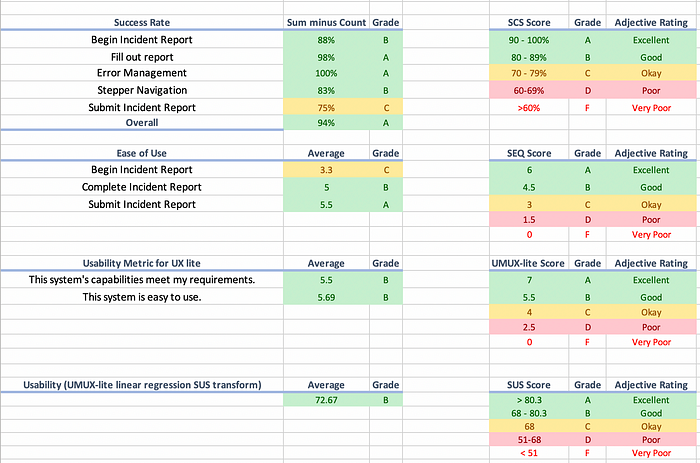
In contrast, chronic, or long-term, testing would be in addition to acute testing. It would probably include the manual testing that is done as features are being added to an application. Each team of a consuming application would be responsible to ensure that each new visual experience matches the new design tokens.
The gap in the chronic testing is that it doesn’t account for ensuring that the initial migration to the new design system was completely successful. In other words, there could be unofficial specifications that are still floating around in legacy experiences/code.
That highlights the need for acute testing, scoring how each application adopted the new design system.
This is especially true as the teams for each consuming application are probably busy building features. It’s not far-fetched to imagine a design system migration coming up short of flawless.
So what would be done for acute testing?
The design team may take an inventory of all the consuming applications and their stakeholders. From there, they may score each application.
This scoring may be a bit easier than something like the graphic above.
You can get more sophisticated but a good place to start maybe just to ensure that all styles in an application match the styles represented in an official design token.
Sounds great but is there any way to automate this?
I’ve recently dug into that question myself and come up with a proof-of-concept solution for web applications.
I’ll unpack that solution in this article. This will be more of a “how I did this” than a “let’s do this” article.
The Concept
Ok, so we want to attempt to automate the scoring of a web application’s adoption of new design tokens.
What do we need?
First things first, we would need access to the official design tokens.
A design team would already have access to this.
Second, we would need the implemented specifications (key-value pairs) within an application.
Extracting these specifications is not as easy but it’s possible (more on that later).
If we had the official specifications (design tokens) and the actual specifications of an application (key-value pairs), then would compare the two sets of specifications against one another.
We could see where the actual specifications differed from the official specifications, allowing us to determine a score.
We could tally every time where there was a valid/correct/official specification as well as every time there was an invalid/incorrect/unofficial specification.
With some basic math, we could provide a final score/grade as well as some metrics to summarize.
Think of something like Google Lighthouse:
Now, to compare the official set of specifications with the actual specifications, there needs to be a way to associate the value of the actual specification with all the valid values in the set of official specifications. This is the third thing we need.
This is best illustrated with an example.
Let’s say we have the following official design tokens:
export const COLOR_PRIMARY = "blue";
export const COLOR_SECONDARY = "red"
export const COLOR_ACCENT = "magenta";
export const FONT_WEIGHT_LIGHT = 300;
export const FONT_WEIGHT_DEFAULT = 400;
export const FONT_WEIGHT_BOLD = 600;
Using some hypothetical tooling, we grab the official specifications from an application:
const actualSpecifications = [
{ prop: "background-color", value: "yellow" },
{ prop: "font-weight", value: 300 }
]
To generate a score, we would iterate through
actualSpecifications.
Then, we would have to know that background-color pertains to the
design tokens that are named with COLOR, not
FONT_WEIGHT.
Finally, we see if the current specification’s value (yellow)
matches any of the official specifications (blue,
red, green).
Since it does not, it’s detected as an unofficial value.
Next, the font weight specification would be matched with the
FONT_WEIGHT design tokens, and given that it matches the official
FONT_WEIGHT_LIGHT specification, it would be detected as an
official value.
We could create a “report” that brings to attention the unofficial values as well as the overall summary:
{
unofficial: [
{
prop: "background-color",
value: "yellow",
},
],
summary: {
color: {
correct: 0,
incorrect: 1,
percentage: "0%",
},
fontWeight: {
correct: 1,
incorrect: 0,
percentage: "100%",
},
overall: {
correct: 1,
incorrect: 1,
percentage: "50%",
grade: "F",
},
},
}
Taking it one step further, we could also use simple algorithms to determine the nearest official value for the unofficial values that were detected:
{
unofficial: [
{
prop: "background-color",
value: "yellow",
officialValue: "red"
},
],
summary: { ... },
}
Pretty cool!
The Technology (High-Level)
Cool example but what exactly could something like this all come together?
The first challenge is finding a way to extract CSS from a site.
My first inclination was to create use a browser API, like Puppeteer or
Cypress, that would accumulate all the computed styles using
window.getComputedStyle.
I went down this path only to realize that this was a larger effort than I had predicted. I decided to double-check if there was something like this available as a package.
Thanks to a peer, I stumbled across a cool project called Wallace that had some relevant open source tools.

In particular, I noticed the extract-css-core tool that exposes an API to get all styles, including client-side, server-side, CSS-in-JSS, as well as inline styling.
By calling the API with a site URL, all the CSS could be extracted.
If we have CSS with all the styles for a site, then the power of PostCSS can be utilized.
PostCSS exposes an API with the potential to traverse all the CSS declarations and do something with them.
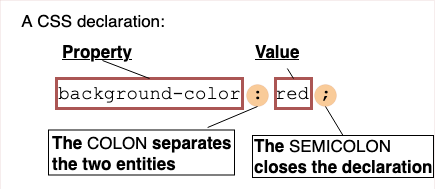
Each CSS declaration is composed of a property and value. In other words, it’s a key-value pair that represents a specification, which is exactly what we want to look at.
We could create a PostCSS plugin that processes the extracted CSS. It would take in the official specifications (the design tokens) as an option, iterates through the declarations, and determine if the declaration is valid/official or invalid/unofficial, firing callbacks when this occurs.
We would then need something that receives a site URL and the design tokens.
It would have code that calls the
extract-css-core API to extract the CSS, then it would process
the CSS using the PostCSS API. The PostCSS API would utilize a custom plugin
as was just mentioned.
A good fit for that would be a CLI. We could create a CLI that receives a site URL and the design tokens as arguments and then does the rest of the work.
Finally, the CLI tool could print the “report” (let’s call it “scorecard”) in the terminal. Or, it could print the scorecard as a JSON blob, depending on the arguments provided.
The Technology (Low-Level)
There are several layers that we could dig into, but let’s start with how the
extract-css-core and postcss API would be used.
Assuming the PostCSS plugin has already been implemented (more on that later), the usage of it would look like this:
const css = extractCSS(site);
let invalidScores = [];
let validScores = [];
await postcss()
.use(
scorecard({
onInvalid: (score) => {
// Accumulate the invalid "scores"
// A "score" is an object containg the specification as well as its category/type
invalidScores.push(score);
},
onValid: (score) => {
// Accumulate the valid scores
validScores.push(score);
},
onFinished: () => {
// Do the math get the percentage of valid scores / total scores
// These calculations could be gathered by category
// A category would just be a subset of the set of valid and invalid scores where `score.type === [CATEGORY]`
// These metrics can be printed as tables using some Node package
console.log(unofficialTable);
console.log(summaryTable);
// Or, write to a JSON file
fs.writeFileSync(output, JSON.stringify(report));
},
specs, // the official design tokens
})
)
.process(css, { from: undefined });
The code snippet above could be part of a CLI command. The Open CLI Framework is a great option for bootstrapping the work that goes into a CLI.
The CLI could be used like so:
USAGE
$ my-cli scorecard -s https://www.figma.com/developers -t ./tokens.js
OPTIONS
-s, --site=site site url to analyze
-t, --tokens=tokens relative path to tokens file
-j, --json=json (optional) flag to enable printing output as a JSON blob; requires -o, --output to be set
-o, --output=output (optional) relative path for a JSON file to output; requires -j, --json to be enabled
DESCRIPTION
...
Scorecard analyzes a web app or web page,
collecting design system adoption metrics
and insights for adoption.
Finally, let’s unpack the real meat and taters…the PostCSS plugin.
Here’s what the shell of the plugin would look like:
module.exports = (options) => {
const {
onFinished = noop,
onInvalid = noop,
onValid = noop,
specs,
} = options;
return {
postcssPlugin: "postcss-scorecard",
Once(root) {
root.walkDecls((declaration) => {
// The key and value of an actual specification
const { prop, value } = declaration;
// Use a utility to get the type/category of the prop
// This can be done using matchers
// For example, the RegExp `/margin|padding/g`
// would determine that a specification is a "spacing" type
const type = getType(prop);
// Grab the matcher that is relevant to the declaration
// For example, `/color/g` when the prop is `background-color`
const matcher = getMatcher(prop);
// Extract the official specs revelant to the declaration
// For example, it would return
// `{ fontWeight: [300, 400, 600] }`
// when the declaration is a font weight type
// (using the example tokens listed earlier)
const officialSpecs = extractSpecs(specs, matcher);
const isOfficialColor = officialSpecs.color.includes(value);
if (types === types.COLOR && !isOfficialColor) {
// return an invalid "score" object
onInvalid({
type,
prop,
value,
// Use `nearest-color` to find nearest official value
// https://www.npmjs.com/package/nearest-color
nearestValue: require('nearest-color').from(officialSpecs.colors)(value),
context: declaration,
})
} else {
onValid({
type,
prop,
value,
context: declaration,
})
}
// Tell the CLI to do the calculations and print the report
onFinished();
},
};
};
module.exports.postcss = true;
I’ve skipped over a lot of the underlying logic. However, I’ll point you to my solution so you can fill in the blanks.
The Project
Now that I’ve given you the shell of how we could automate acute, scorecard testing using an Oclif CLI and PostCSS, you can review the open-source project that I’ve put together.
Tempera: https://github.com/michaelmang/tempera
A CLI toolkit for aiding design tokens adoption.
Docs: https://tempera.netlify.app/


Feel free to review the source code to fill in the blanks. Any feedback and/or contribution is welcome. 🚀
The Limitations, & Roadmap
The biggest limitation is that an application that is consuming design tokens will likely require authentication. A potential solution is to add a headless Puppeteer, Cypress, or Playwright script to authenticate into the application, then the CSS could be extracted.
The next biggest limitation is that the design tokens have to be named to work with the matchers. Meaning, the kebab case of the design token key has to match against the matcher. This means that the naming of the design tokens could be driven by the tooling, which is backward. It is hard to generalize the token extraction. One workaround would be to expose an option to provide custom matchers.
Another gotcha is handling differences between units (like
px versus rem). I added another plugin in the
PostCSS chain that precedes the plugin I created. This
plugin can convert from
pixels to rem. However, I found it to be a bit spotty. Additionally, you have
to be careful to make the official and unofficial specifications be of the
same unit when doing calculations, do you’d want to convert them back to their
respective units so that the final report is accurate. I have not implemented
this.
Lastly, I had to add another
plugin
to the PostCSS chain to expand all the CSS properties to longhand (i.e.
background --> background-color). This also
appeared to be a bit spotty.
As far as the roadmap, I would love to address all the limitations mentioned above.
Additionally, I think there is an opportunity to automatically update the CSS to the nearest official value. This could be a fallback in the bundle when used with postcss-loader. Or, it could be an option in the CLI tool which could be used for one-time migrations.
Even better, a stylelint plugin could be written to catch unofficial values during local development.
There is also the ability to generate custom reporters, notifications, documentation, etc. on top of the JSON that the CLI tool can export.
Finally, the automation could expand beyond just comparison values from set A and set B. It could also report on other useful CSS states. Wallace seems to be on the right track with this. Perhaps, it could be leveraged.
Conclusion
Thanks for tuning in to another experiment in my design tokens journey.
I hope this article helps stir up ideas for further design tokens automation, even if the solution looks completely different.
And once again, here is the final project I created:
Tempera: https://github.com/michaelmang/tempera
Don’t be shy in providing feedback.
That’s all folks. Pow, share, and discuss!

